

One of the tasks of administrator is to estimate size of the database. But how to do this? As input for the task dba can receive: structure of the database and estimated number of records in each database. Generally this should be enough...
Having structure of objects in the database, objects like procedures, functions, views can be ommitted in estimation. Those objects don't contain data, so they are small. No worries.
What is important are tables and indexes. But no worries again, as Sybase dba has very useful procedure sp_estspace!
Let's suppose a database contains table of following structure:
CREATE TABLE Document (ID INT IDENTITY PRIMARY KEY CLUSTERED, NAME VARCHAR(50) NOT NULL, DESCRIPTION VARCHAR(200) NULL, DATE DATETIME DEFAULT GETDATE())
Additionally following index has been created:
CREATE NONCLUSTERED INDEX IX_DOCUMENT_NAME ON Document(NAME)
Let's suppose, we expect the table will have 100.000 rows during one year's time. Following command will help to estimate the size of such table:
EXEC sp_estspace 'Document', 100000
Here the results:
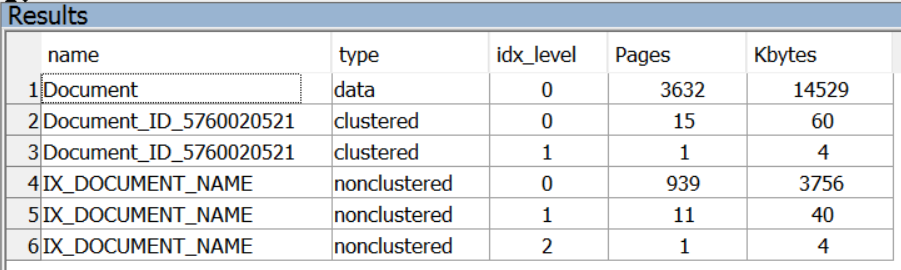
The first result set shows:
- space that will be taken by data - here 3632 pages
- space that will be consumed by clustered index (during creation of the index, it was not named, so some system name has been assigned here). That index will have two levels in B-Tree: one (root) of size 1 page and the another (lover one on level 0) of size 15 pages
- space that will be occupied by non clustered index IX_DOCUMENT_NAME. Here 3 levels are expected to appear: root - level 2 - 1 page, intermediate - level 1 - 11 pages and finally lower level 0 - 939 pages
Nice! Isn't it!?
And here the second result set:

Here only one general information can be found. Probably this information answers the best the question regarding the size of the table.It will take around 18 MB.
The last result set is:

This is a summary generated for clustered index and all non clustered indexes without separating the data into different levels of indexes, just summary.
In my opinion very easy and smart solution!

No comments:
Post a Comment